ПО «Надежность»
24 февраля 2026
Что такое Data Governance: определение, риски и уровни зрелости

Автор статьи:
Артём Смирнов |
Что такое Data Governance?
В условиях тотальной цифровизации информация становится главным активом предприятия. Однако просто собирать данные недостаточно – ими нужно уметь управлять. Data Governance – это система, гарантирующая, что данные на всех этапах своего жизненного цикла остаются качественными, доступными, защищенными и, что самое важное, приносящими прибыль.
Многие путают Data Governance с простым управлением базами данных, но разница в том, что это «надстройка» над всеми ИТ-процессами. Она отвечает не за то, как технически сохранить информацию, а за то, кто имеет на это право, какие стандарты качества должны соблюдаться и каким образом данные помогают достигать бизнес-целей. Без устанавливающих правил Data Governance, цифровизация производства превращается в «хаос на входе – хаос на выходе».
Чтобы понять, где вы сейчас и сколько вложений нужно в Data Governance, не требуется консультант за 2 млн рублей. Достаточно честно ответить на 15 вопросов и понять свой уровень. Ниже — практичная модель зрелости в 4 уровнях, адаптированная под ТОиР.
Что включает Data Governance:основные элементы
Реализация стратегии управления данными – это не разовый проект, а непрерывный процесс. Чтобы система Data Governance работала, она должна охватывать пять критических областей:
-
Data Quality (Управление качеством данных): Это фундамент. Сюда входит очистка данных, дедупликация и проверка на соответствие бизнес-правилам. Внедрение автоматических метрик, которые отсекают «грязные» данные до того, как они попадут в отчеты топ-менеджмента.
-
Metadata Management (Управление метаданными): Чтобы данные были полезны, у них должен быть контекст. Метаданные отвечают на вопросы: Откуда пришел этот показатель? Кто его изменил? Как он связан с другими таблицами? Это создает прозрачную карту данных (Data Lineage).
-
Data Security & Privacy (Безопасность и конфиденциальность): В рамках DG определяются политики доступа. Мы четко регламентируем, кто может видеть чувствительную коммерческую информацию или персональные данные, минимизируя риски утечек и штрафов.
-
Data Stewardship (Институт ответственных): На практике DG невозможен без распределения ролей. Data Stewards – это бизнес-эксперты, которые отвечают за содержание данных, а Data Custodians – ИТ-специалисты, отвечающие за техническую сохранность.
-
Master Data Management (MDM): Создание «единого источника правды» для мастер-данных (справочники контрагентов, номенклатура оборудования, клиентские базы). Это исключает ситуацию, когда в разных системах одна и та же деталь называется по-разному.
Что дает внедрение Data Governance компании?
-
Радикальное ускорение принятия управленческих решений. В компаниях без выстроенного Data Governance до 70% времени аналитиков уходит на поиск данных и подтверждение их актуальности.
-
Ликвидация операционных рисков и «стоимости ошибок». Низкое качество данных напрямую конвертируется в финансовые потери: дублирование заказов, ошибки в логистических накладных, путаница в складских остатках и реквизитах контрагентов.
-
Формирование качественной аналитики. Часто разные департаменты (например, финансы и производство) показывают разные цифры по одним и тем же KPI из-за различий в методологии сбора данных.
-
Масштабируемость и высокая адаптивность ИТ-ландшафта. При расширении бизнеса, открытии новых филиалов или поглощении активов интеграция данных часто становится «бутылочным горлышком».
Уровень 0. Хаос в Excel
Признаки:
- Справочники активов, отказов и работ ведутся в Excel или вообще не ведутся.
- Каждый цех/участок называет оборудование и коды отказов по своему.
- Нет единой иерархии активов (один и тот же актив называется по разному в SAP, у мастера и в IoT системе).
- «Прочее» или пустые поля в 30–50% нарядов.
- Нет владельцев данных — "кто хочет, тот и правит".
- Для подготовки отчёта аналитик собирает данные вручную из 5–10 источников и сводит в отдельный Excel.
- Данные из IoT не связаны с активами и историей отказов.
Риски:
- Невозможно посчитать реальный MTBF, MTTR или эффект от внедрений.
- Любая попытка аналитики превращается в археологию ("где та таблица?").
- Предиктивные модели на таких данных не обучаются — мусор на входе, мусор на выходе.
- Дублирование работы: каждый отчёт — с нуля, каждый проект RCM начинается с "давайте сначала наведём порядок в справочниках".
Что делать:
Переходите на Уровень 1: хотя бы соберите всё в одно место и договоритесь о базовых правилах.
Уровень 1. Локальные реестры в ERP
Признаки:
- Активы заведены в ERP (SAP/1С), есть иерархия.
- Работы ТОиР фиксируются в системе, но справочники отказов — либо минимальны, либо дублируются в Excel у инженеров.
- Есть базовые коды проблем в SAP, но они не стандартизированы (10–15 кодов типа "износ", "прочее", "поломка").
- Данные качества низкие: 20–40% нарядов с "прочее" или без кода.
- Владельцы данных формально назначены (главный механик, начальник ТОиР), но не следят за качеством активно.
- IoT данные существуют, но живут отдельно от ERP.
- Нет регламентов на добавление активов или кодов — "как получится".
Риски:
- Можно посчитать базовые метрики (количество нарядов, затраты), но глубокая аналитика по режимам отказов не работает.
- Сравнение между цехами затруднено (коды называются по разному).
- RCM/FMECA строится заново для каждого проекта, без переиспользования знаний.
- Предиктив возможен только точечно, на отдельных активах с чистыми данными.
- Механизмы контроля (начальные):
- Обязательное заполнение полей актива и кода проблемы в SAP при закрытии наряда (жёсткая валидация на уровне транзакции).
- Периодические отчёты по качеству данных (доля "прочее", пустые поля) — раз в квартал.
Механизмы контроля (начальные):
- Обязательное заполнение полей актива и кода проблемы в SAP при закрытии наряда (жёсткая валидация на уровне транзакции).
- Периодические отчёты по качеству данных (доля "прочее", пустые поля) — раз в квартал.
Что делать:
Переходите на Уровень 2: стандартизируйте справочники, введите регламенты и подключите отраслевой слой (ТООН/ИСМД).
Уровень 2. Единая модель данных в ТООН/ИСМД с контролем качества
Признаки:
- Справочники активов, функций, режимов отказов и FMECA ведутся в отраслевом решении (ТООН, ПО «Надёжность»).
- Синхронизация с SAP: мастер данные активов в SAP, расширенная модель (функции, критичность, FMECA) — в ТООН.
- Справочники отказов стандартизированы по ISO 14224 или собственному каталогу, "прочее" < 10%.
- Назначены владельцы данных по каждому справочнику с чёткими обязанностями.
- Регламенты на добавление активов, кодов отказов, изменение критичности описаны и выполняются.
- Автоматический контроль качества данных: дашборды показывают доли пустых/некорректных полей, дубликаты, коды "прочее".
- IoT данные связаны с активами через единый ID, временные ряды попадают в Data Lake.
- История отказов хранится структурированно с привязкой к RCA и мерам.
Риски (остаточные):
- Всё ещё есть "островки" данных в Excel (у отдельных специалистов).
- Качество данных зависит от дисциплины мастеров — автоматизированная валидация работает, но не покрывает 100% кейсов.
- Обогащение данных (например, добавление функций к старым активам) идёт медленно.
Механизмы контроля в ТООН/ИСМД:
1. Обязательные поля при создании актива:
- ID, наименование, тип, иерархия, функция, критичность (A/B/C из FMECA).
- Система не даёт сохранить актив без этих полей.
2. Валидация кодов отказов при закрытии наряда:
- Выбор только из справочника (нельзя ввести свободный текст).
- Для кода "прочее" обязательно текстовое пояснение (минимум 20 символов).
3. Автоматические проверки качества:
- Еженедельные отчёты: доля нарядов без кода отказа, с "прочее", с пустыми полями.
- Дашборды для владельцев данных: топ 10 некорректных записей, дубликаты активов, активы без функции.
4. Регламенты на изменение справочников:
- Запрос на добавление кода отказа → согласование владельца → публикация → синхронизация в SAP.
- История изменений справочников хранится (кто, когда, зачем).
5. Связка IoT и активов:
- Каждый датчик привязан к активу через ID.
- Аномалии в IoT данных (пропуски, выбросы) фиксируются и сигнализируются.
6. RCA и меры хранятся структурированно:
- Для критичных отказов обязательна запись RCA (непосредственная причина → содействующие факторы → коренная причина).
- Меры привязаны к отказам и отслеживаются (выполнено/не выполнено).
Что даёт:
- Можно строить глубокую аналитику по режимам отказов, MTBF, повторяемости.
- RCM/FMECA становится живым документом, а не "сделали раз и забыли".
- Предиктивные модели обучаются на качественных данных и дают результат.
- Сравнение между цехами, участками, заводами становится возможным (единые коды и метрики).
Что делать:
Переходите на Уровень 3: автоматизируйте обогащение данных, внедряйте ML модели для валидации и предиктива.
Уровень 3. Оптимизированная система с ML и автоматизацией
Признаки:
- Data Governance встроен в культуру: владельцы данных активно работают, регламенты выполняются без напоминаний.
- Автоматическое обогащение данных: ML модели предлагают коды отказов на основе текстового описания проблемы (мастер подтверждает или корректирует).
- Предиктивная валидация: система предупреждает о подозрительных записях (например, "код износа" для нового актива с наработкой 100 часов).
- IoT аномалии автоматически создают заявки или сигналы в ТООН.
- Полная прослеживаемость: от IoT события → отказ → RCA → меры → эффект.
- Data Lake используется для обучения ML моделей прогнозирования отказов.
- Качество данных > 95%: "прочее" < 5%, пустые поля < 2%.
- Автоматические отчёты и дашборды для всех уровней (от мастера до директора).
Риски (минимальные):
- Требуются инвестиции в поддержание ML моделей (переобучение, валидация).
- Высокая зависимость от квалификации команды Data Governance.
Механизмы контроля (продвинутые):
1. ML ассистенты для заполнения:
- Мастер описывает проблему текстом → система предлагает 3 подходящих кода отказа.
- Мастер выбирает или корректирует → модель учится.
2. Предиктивная валидация:
- "Этот код обычно не используется для данного типа актива — вы уверены?"
- "Наработка актива слишком мала для режима отказа 'усталость материала'".
3. Автоматическое обнаружение дубликатов и аномалий:
- Два актива с похожими названиями → сигнал владельцу данных.
- Резкий рост кода "прочее" в конкретном цехе → расследование.
4. Обратная связь по качеству мер:
- Для каждой меры из RCA отслеживается: выполнена ли, снизилась ли частота отказа после неё.
- Неэффективные меры помечаются для пересмотра.
5. Прогнозирование отказов:
- ML модели на IoT + история отказов → "вероятность отказа этого актива в ближайшие 7 дней: 78%".
- Автоматическое создание заявки или сигнала инженеру.
Что даёт:
- Переход от реактивного к предиктивному управлению.
- Экономия времени мастеров (автоматические подсказки, минимум ручной работы).
- Высокая точность аналитики и прогнозов.
- Data Governance становится конкурентным преимуществом.
Итог
Data Governance — это не про "навести красоту в данных ради красоты". Это про возможность предотвращать отказы, а не героически их устранять. Уровень 0–1 — вы тушите пожары. Уровень 2 — вы видите, где они начнутся. Уровень 3 — вы их не допускаете.
Начните с чек листа выше и двигайтесь пошагово: сначала справочники и регламенты, потом контроль качества, потом — автоматизация и ML.
Как оценить свой уровень (самодиагностика за 10 минут)
Ответьте "да" или "нет":

Результаты:
• 0–3 "да" → Уровень 0 (хаос в Excel)
• 4–6 "да" → Уровень 1 (локальные реестры в ERP)
• 7–9 "да" → Уровень 2 (единая модель в ТООН/ИСМД)
• 10 "да" + ML/автоматизация → Уровень 3 (оптимизированная система)

Похожие материалы
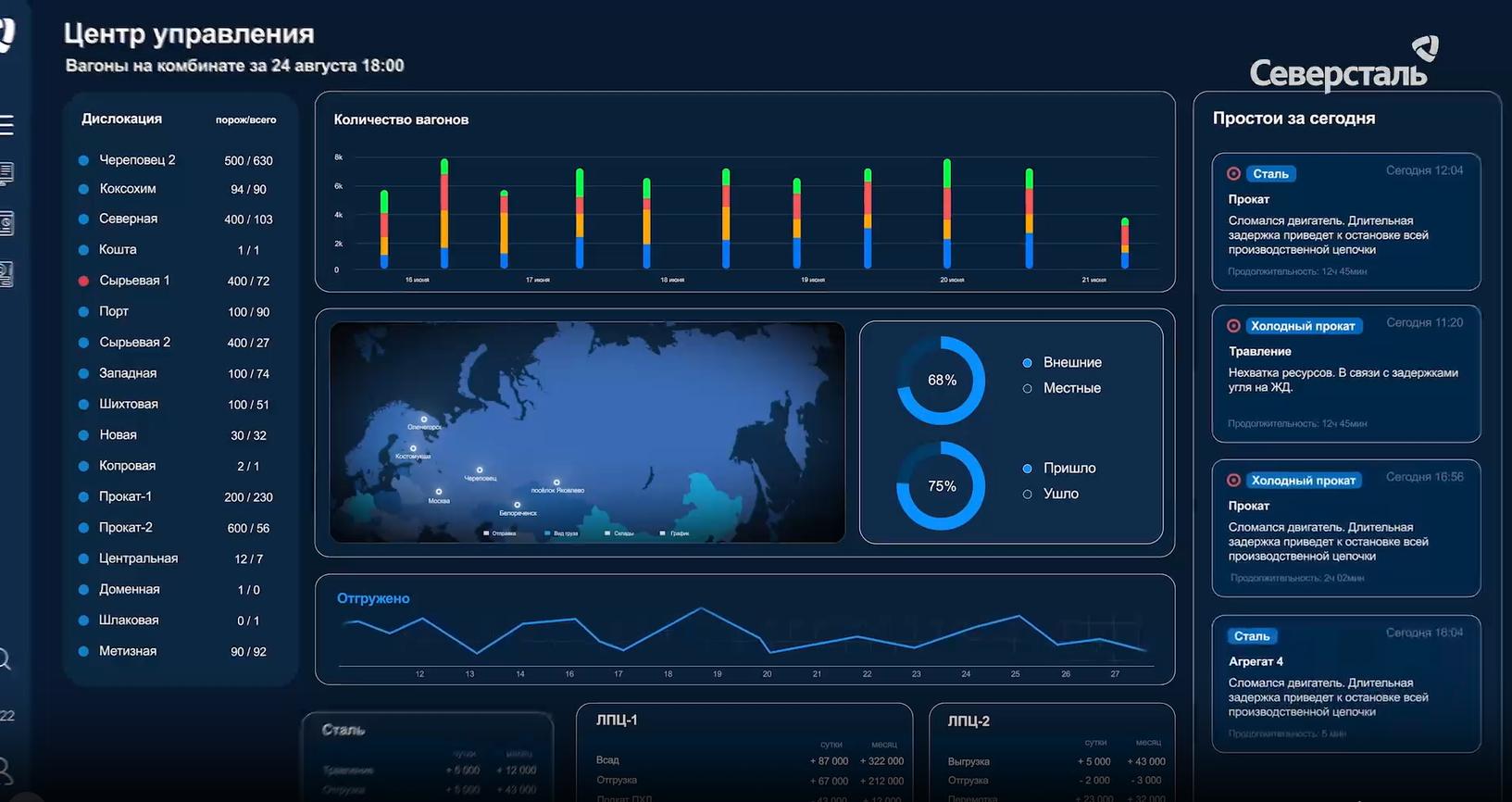


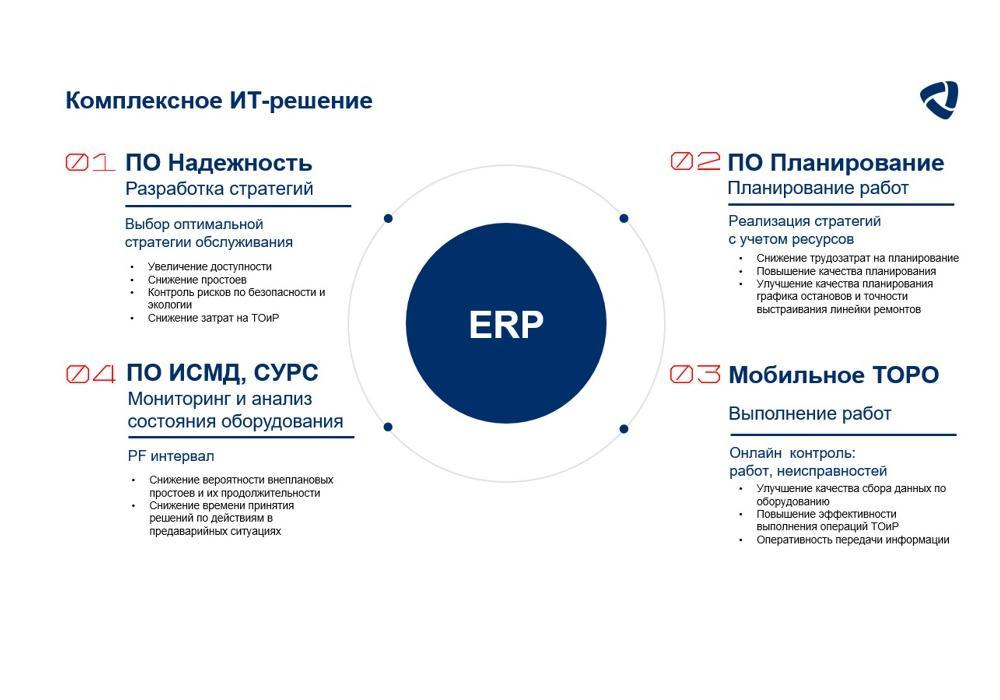
Ваш вопрос отправлен!